System framework of baseline model MM-Net.
System framework of baseline model MM-Net.
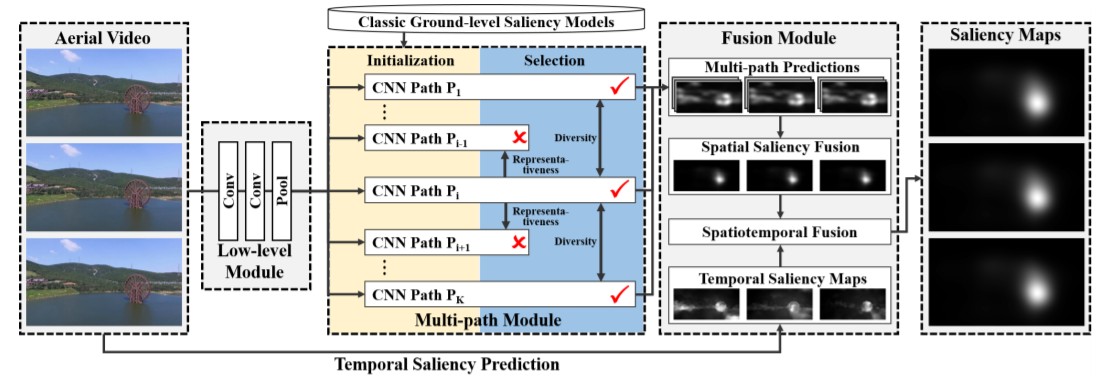
As an emerging vision platform, a drone can look from many abnormal viewpoints which brings many new challenges into the classic vision task of video saliency prediction.To investigate these challenges, this paper proposes a large-scale video dataset for aerial saliency prediction, which consists of ground-truth salient object regions of 1,000 aerial videos,annotated by 24 subjects. To the best of our knowledge, it is the first large-scale video dataset that focuses on visual saliency prediction on drones. Based on this dataset, we propose a Model-guided Multi-path Network (MM-Net) that serves as a baseline model for aerial video saliency prediction. Inspired by the annotation process in eye-tracking experiments, MM-Net adopts multiple information paths, each of which is initialized under the guidance of a classic saliency model. After that, the visual saliency knowledge encoded in the most representative paths is selected and aggregated to improve the capability of MM-Net in predicting spatial saliency in aerial scenarios. Finally, these spatial predictions are adaptively combined with the temporal saliency predictions via a spatiotemporal optimization algorithm. Experimental results show that MM-Net outperforms ten state-of-the-art models in predicting aerial video saliency.

Representative frames of state-of-the-art models on AVS1K. (a) Video frame, (b) Ground truth, (c) HFT, (d) SP, (e) PNSP, (f) SSD, (g) LDS, (h) eDN, (i) iSEEL, (j) SalNet, (k) DVA, (l) STS, (m) MM-Net, (n) MM-Net-, (o) MM-Net+.